The $100M AI Training Waste Crisis: Why Single-Cloud Contracts Are Bleeding Money
The $100M AI Training Waste Crisis: Why Single-Cloud Contracts Are Bleeding Money
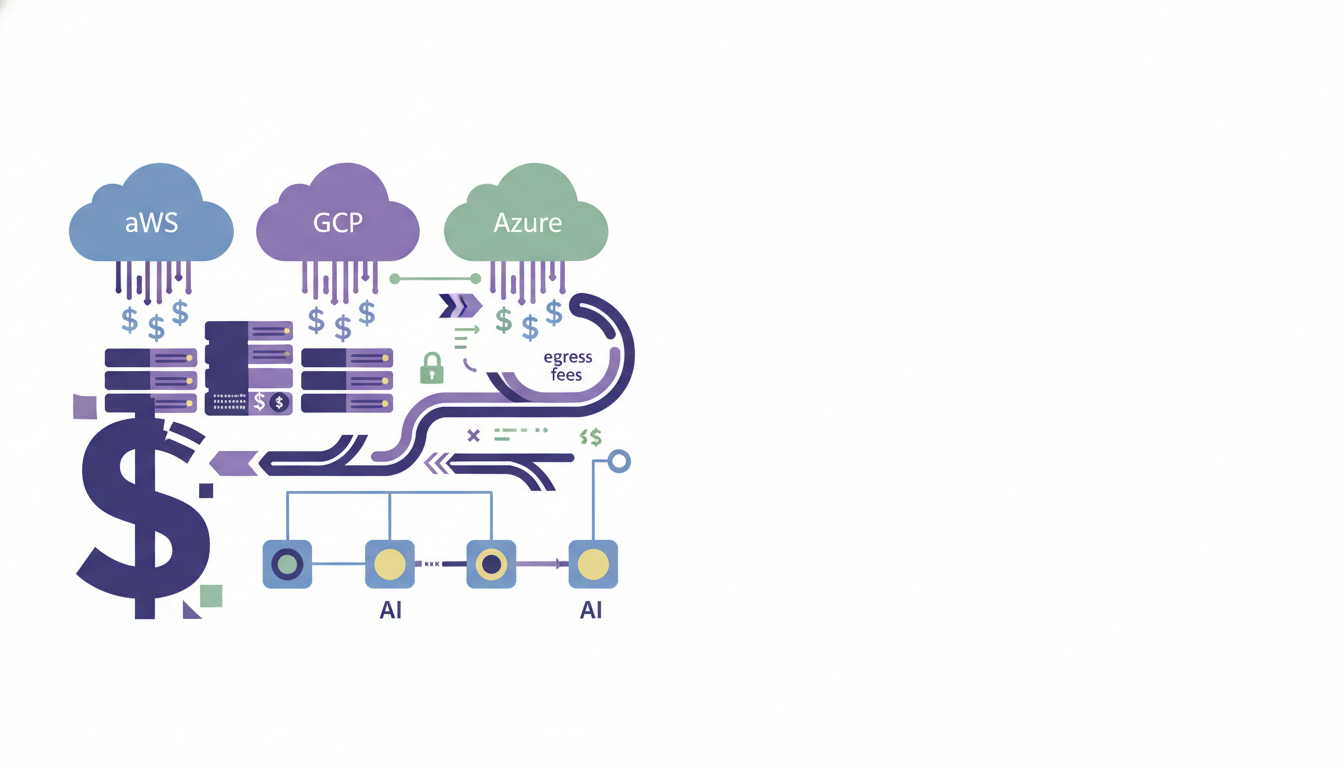
Every major AI company is hemorrhaging money on training costs they don't need to pay. While everyone talks about the staggering expense of frontier model training — GPT-4's $100M+ price tag and Gemini Ultra's $191 million cost — the real scandal isn't how much these models cost. It's how much companies are overpaying.
Training costs are growing at 2.4x per year, but that's only part of the story. The bigger problem is that egress fees and vendor lock-in represent a significant portion of the Cost of Goods Sold (COGS) for AI-driven companies, preventing migration when more efficient GPU architecture becomes available elsewhere.
The Hidden Expense Everyone Ignores
AI training isn't just about GPU compute anymore. When you dig into the real numbers, hardware makes up 47–67% of development costs, while R&D staff costs account for 29–49%. But there's a third category that's quietly draining budgets: the infrastructure tax of being locked into a single cloud provider.
Gartner estimates that data-egress fees consume 10–15% of a typical cloud bill, and for AI workloads, that percentage explodes. Consider this: the cost of moving a petabyte of data can reach up to $90,000. When your training datasets are measured in petabytes and your model checkpoints are hundreds of gigabytes, these "minor" fees become major budget killers.
The Real Cost of Single-Cloud Training
Here's what actually happens when you train a frontier model on a single cloud:
Data gravity becomes a financial prison. If your data resides in an AWS S3 bucket but optimized GPU compute is on a specialized provider, the egress costs from S3 can quickly exceed the cost of the compute itself, creating a phenomenon known as 'data gravity'.
GPU pricing becomes non-negotiable. Hyperscalers are designed to support every imaginable workload, meaning AI-focused organizations often pay for infrastructure flexibility they don't use, leading to premium pricing on GPU instances with costs further escalated by data egress fees.
Idle capacity costs compound. When data is moved for AI training, there are expensive GPUs at both the origin and destination. Companies get stuck paying for GPUs at both locations due to contract commitments.
Why Manual Cloud Arbitrage Fails
Some teams try to solve this with manual cloud arbitrage — moving workloads to wherever GPUs are cheapest. It doesn't work at scale. Managing several cloud providers adds significant operational complexity. Each platform has its own ecosystem, APIs, billing mechanisms, and administrative interfaces. Teams must be competent in all areas, which increases training expenses and operating overhead.
The complexity gets worse with AI workloads. Cloud management options come with a substantial learning curve. Lifecycle management remains tedious and error-prone, often requiring manual trial-and-error steps. DevOps engineers find themselves performing repetitive tasks such as reading cloud documentation, understanding user requirements, and debugging failures.
Egress fees are often non-linear and tiered, varying based on destination and total volume. This complexity makes it nearly impossible for CTOs to accurately predict the final cost of a training run until the bill arrives.
The Economics Are Getting Worse
The math is brutal and getting worse. If the trend of growing training costs continues, the largest training runs will cost more than a billion dollars by 2027. But even as absolute costs rise, 'neo‑clouds' already beat hyperscalers by 30–50% on $/PFLOP for training, and the $10‑plus hyperscaler rate isn't just expensive—it's structurally unsustainable.
65% of enterprises planning GenAI projects say soaring egress costs are a primary driver of their multicloud strategy. Those dollars represent training runs that never happen and product features that ship late.
The Real Solution: Intelligent Cross-Cloud Orchestration
The answer isn't manually juggling cloud providers or accepting vendor lock-in as inevitable. The most successful multi-cloud environments are automated, visible, and constantly improved. To reduce manual intervention, implement policy-driven automation for scaling, cost management, and failover.
What AI companies need is intelligent orchestration that can:
- Automatically migrate workloads to the most cost-effective infrastructure in real-time
- Eliminate data gravity through intelligent checkpointing and seamless data transfer optimization
- Maintain training continuity across cloud boundaries without risk
- Optimize across all variables — not just GPU price, but total cost including egress, networking, and idle capacity
The companies that solve this first will have a massive competitive advantage. While their competitors burn through $100M+ training budgets locked into expensive single-cloud contracts, they'll be training better models for 30-50% less.
The $100 million AI training waste crisis isn't about the absolute cost of computation. It's about paying premium prices for suboptimal infrastructure when better, cheaper options exist just one cloud migration away.
Ready to stop overpaying for AI training infrastructure? Learn how intelligent cross-cloud orchestration can reduce your training costs by 30-50% while ensuring zero training failures. Get started with CloudShift AI and make every training dollar count.
AI/ML Training Infrastructure Management
CloudShift AI is an intelligent cross-cloud training orchestration platform designed for AI-first startups and large tec
Discover what we're building
Learn more about AI/ML Training Infrastructure Management and get started today.
Visit AI/ML Training Infrastructure Management